刚刚看到QQ群有人吹Hashmap,一想我啥都不懂,就赶快补了一波。下面分享一下我对Hashmap的理解,主要用于个人备忘。如果有不对,请批评。想要解锁更多新姿势?请访问https://tengshe789.github.io/
总起
Hashmap是散列表,存储结构是键值对形式。根据健的Hashcode值存储数据,有较快的访问速度。
它的线程是不安全的,在两个线程同时尝试扩容HashMap时,可能将一个链表形成环形的链表,所有的next都不为空,进入死循环;要想让它安全,可以用 Collections的synchronizedMap 方法使 HashMap具有线程安全的能力,或者使用ConcurrentHashMap 。
他的键值对都可以为空,映射不是有序的。
Hashmap有两个参数影响性能:初始容量,加载因子。
Hashmap存储结构
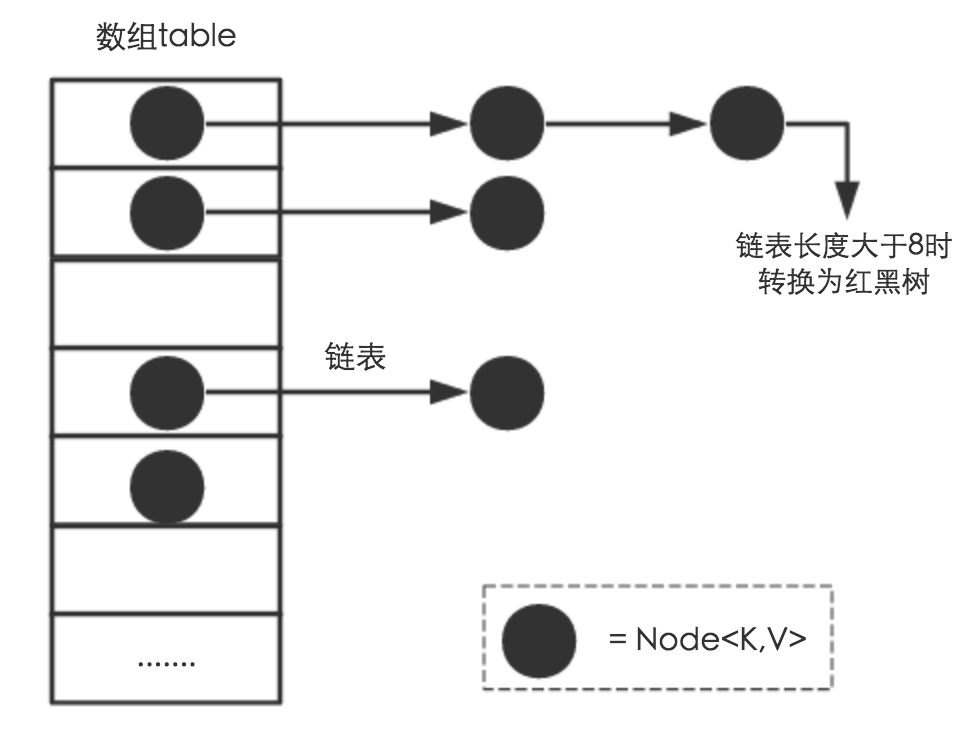
JDK1.8中Hashmap是由链表、红黑树、数组实现的
1 | //用来实现数组、链表的数据结构 |
Hashmap构造方法
HashMap有4个构造方法。
代码:
1 | //方法1.制定初始容量和负载因子 |
Hashmap变量成员
1 | //未指定容量的时候,数组的初始容量。初始容量是16 |
初始容量、负载因子、阈值.
一般情况下,使用无参构造方法创建 HashMap。但当我们对时间和空间复杂度有要求的时候,使用默认值有时可能达不到我们的要求,这个时候我们就需要手动调参。
在 HashMap 构造方法中,可供我们调整的参数有两个,一个是初始容量initialCapacity,另一个负载因子loadFactor。通过这两个设定这两个参数,可以进一步影响阈值大小。但初始阈值 threshold 仅由initialCapacity 经过移位操作计算得出。
| 名称 | 用途 |
|---|---|
| initialCapacity | HashMap 初始容量 |
| loadFactor | 负载因子 |
| threshold | 当前 HashMap 所能容纳键值对数量的最大值,超过这个值,则需扩容 |
默认情况下,HashMap 初始容量是16,负载因子为 0.75。 注释中有说明,阈值可由容量乘上负载因子计算而来 ,即threshold = capacity * loadFactor
1 | static final int tableSizeFor(int cap) { |
这段代码有点难,根据大神的说法,这个方法的意思是,找到大于或等于 cap 的最小2的幂。我们先来看看 tableSizeFor 方法的图解 :

图中容量是229+1,计算后是230
引用一下啊大神说的:
对于 HashMap 来说,负载因子是一个很重要的参数,该参数反应了 HashMap 桶数组的使用情况(假设键值对节点均匀分布在桶数组中)。通过调节负载因子,可使 HashMap 时间和空间复杂度上有不同的表现。当我们调低负载因子时,HashMap 所能容纳的键值对数量变少。扩容时,重新将键值对存储新的桶数组里,键的键之间产生的碰撞会下降,链表长度变短。此时,HashMap 的增删改查等操作的效率将会变高,这里是典型的拿空间换时间。相反,如果增加负载因子(负载因子可以大于1),HashMap 所能容纳的键值对数量变多,空间利用率高,但碰撞率也高。这意味着链表长度变长,效率也随之降低,这种情况是拿时间换空间。至于负载因子怎么调节,这个看使用场景了。一般情况下,我们用默认值就可以了。
插入PUT
过程:
- 对Key求hash值,然后计算下标
- 如果没有碰撞,就放入桶中
- 如果碰撞了,就以链表形式放到后面
- 如果链表长度超过阈值,就把链表转换成红黑树
- 如果链表存在则替换旧值
- 如果桶满了(容量*负载因子),则重新resize
1 | public V put(K key, V value) { |
putVal
核心算法在putVal()中。要想理解,先要明白桶排序(Bucket Sort)
它是迄今为止最快的一种排序法,其时间复杂度仅为Ο(n),也就是线性复杂度。
桶排序核心思想是:根据数据规模n划分,m个相同大小的区间 (每个区间为一个桶,桶可理解为容器) 。将n个元素按照规定范围分布到各个桶中去 ,再对每个桶中的元素进行排序,排序方法可根据需要,选择快速排序,或者归并排序,或者插入排序 ,然后依次从每个桶中取出元素,按顺序放入到最初的输出序列中(相当于把所有的桶中的元素合并到一起) 。
下面是代码:
1 | final V putVal(int hash, K key, V value, boolean onlyIfAbsent, |
HASH
hash算法,高十六位与低十六进行异或运算,这样做的好处是使得到结果会尽可能不同。
1 | static final int hash(Object key) { |
resize
HashMap 的扩容机制与其他变长集合的套路不太一样,HashMap 按当前桶数组长度的2倍进行扩容,阈值也变为原来的2倍(如果计算过程中,阈值溢出归零,则按阈值公式重新计算)。扩容之后,要重新计算键值对的位置,并把它们移动到合适的位置上去。
resize总共做了3件事,分别是:
- 计算新桶数组的容量 newCap 和新阈值 newThr
- 根据计算出的 newCap 创建新的桶数组,桶数组 table 也是在这里进行初始化的
- 将键值对节点重新映射到新的桶数组里。如果节点是 TreeNode 类型,则需要拆分红黑树。如果是普通节点,则节点按原顺序进行分组。
1 | //resize()函数在size > threshold时被调用 |
关于HashMap在什么时候时间复杂度是O(1),什么时候是O(n),什么时候又是O(logn)的问题
O(1):链表的长度尽可能短,理想状态下链表长度都为1
O(n):当 Hash 冲突严重时,如果没有红黑树,那么在桶上形成的链表会变的越来越长,这样在查询时的效率就会越来越低;时间复杂度为O(N)。
O(logn):采用红黑树之后可以保证查询效率O(logn)
手写
1 | /** |
参考资料
感谢!
以下来自n天后的我:
补充一下看到一个非常好的:点击链接,值得学习
