大多数情况下,只要不涉及线程安全问题,Map基本都可以使用HashMap,不过HashMap有一个问题,就是迭代HashMap的顺序并不是HashMap放置的顺序。HashMap的这一缺点往往会带来困扰,因为有些场景,我们需要一个有序的Map。LinkedHashMap就可以做到,它虽然增加了时间和空间上的开销,但是通过维护一个运行于所有条目的双向链表,LinkedHashMap保证了元素迭代的顺序。想要解锁更多新姿势?请访问https://tengshe789.github.io/
数据结构
打开源码可以看到:
1 | /** |
LinkedHashMap继承了HashMap的Entry,并新增加了两个指针
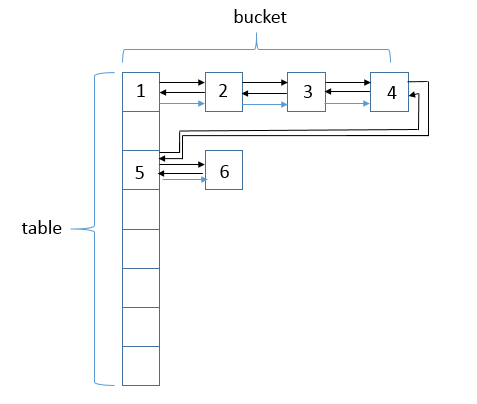
参照一下网络上搜刮的图片,可以看出数据结构为数组 + 单链表 + 红黑树 + 双链表,比HashMap多了一个双向链表,就是利用了头节点和其余的各个节点之间通过 Entry 中的 after 和 before 指针进行关联。
构造方法
看一下构造方法。
1 | public LinkedHashMap(int initialCapacity, float loadFactor) { |
有四个构造方法,每一个的构造方法第一句话基本都是调用父类HashMap方法。估计是用多态来实现的相关功能。比 HashMap 多了一个 accessOrder 的参数,用来指定按照 LRU 排列方式还是顺序插入的排序方式
添加
看 LinkedHashMap 的 put() 方法之前先看看 HashMap 的 putVal 方法:
1 | final V putVal(int hash, K key, V value, boolean onlyIfAbsent, |
其实这篇已经是我早有准备的,第一次看源码的时候已经惊了。LinkedHashMap 自己没有重写put方法,全是照着他爹搬过来的,无赖 啊。代码中敲黑板位置,是LinkedHashMap 重写了 afterNodeAccess() 这个方法。
1 | //将最近使用的Node e,放在链表的最末尾 |
结束
此片完了~ 想要了解更多精彩新姿势?请访问我的个人博客 本篇为原创内容,已在个人博客率先发表,随后CSDN,segmentfault,juejin同步发出。如有雷同,缘分呢兄弟。赶快加个好友~
