今天来回顾一下简单的排序思想,留作今后的复习和备份用。本篇是非常非常基础的,甚至都不会讲实际项目真正能用的排序方法,譬如双轴快速排序 。写的不好请多多谅解。
想要解锁更多新姿势?请访问我的博客
准备阶段
相关功能函数
为了保持代码的整洁,先创造好对数器和相关功能性函数。
交换器
两个数组中的元素比较排序过程中,一定会有元素的交换操作。为了保持代码的整洁,先写出交换操作的函数。
1 | public static void swap(int[] arr, int i, int j) { |
随机样本产生器
自己编数组太麻烦了,让他自己生产吧
1 | public static int[] generateRandomArray(int maxSize, int maxValue) { |
对数器
对数器其实就是一个绝对正确但是复杂度不好的方法。
1 | public static void comparator(int[] arr) { |
说说Arrays.sort()的逻辑吧。数组进入方法,先判断。如果数组的长度小于QUICKSORT_THRESHOLD(默认值是286)的话,再判断,如果数组长度小于INSERTION_SORT_THRESHOLD(值为47)的话,那么就会用插入排序 ,否则就会使用双轴快速排序。
如果大于286呢,它就会坚持数组的连续升序和连续降序性好不好,如果好的话就用归并排序,不好的话就用快速排序。
比较器
比较两个数组一不一样~
1 | public static boolean isEqual(int[] arr1, int[] arr2) { |
打印器
1 | public static void printArray(int[] arr) { |
复制器
1 | public static int[] copyArray(int[] arr) { |
主函数
1 | public static void main(String[] args) { |
脑子
脑阔疼
正篇
基于比较的排序
冒泡排序
原理
冒泡排序算法的原理如下:
- 比较相邻的元素。如果第一个比第二个大,就交换他们两个。此时这两个数,永远是后面的数大。
- 第一回合将每一对相邻元素做同样的工作。回合结束后,最后的元素是整个数组最大的数。
- 第二回合…第n回合过程中,对除了最后一个元素重复以上的步骤。
实现
1 | public static void bubbleSort(int[] arr) { |
复杂度
时间复杂度:O(N²)
额外空间复杂度:O(1)
选择排序
原理
1.第一回合,将指针指向第一个元素,将第一个元素和剩余的元素比较,最小的元素放到一号位置。
2.第二回合…第n回合过程中,指针加一。对除了第一个元素重复以上的步骤。
实现
1 | public static void selectionSort(int[] arr) { |
复杂度
时间复杂度:O(N²)
额外空间复杂度:O(1)
插入排序的
原理
1.第一回合,比较第一个元素和第二个元素大小,大的放在第二个位置上
2.第二回合,将第三个元素与第二、第一个元素比较,大的放在第三个位置上
3.轮回
实现
1 | public static void insertionSort(int[] arr) { |
复杂度
时间复杂度:O(N²)
额外空间复杂度:O(1)
堆排序
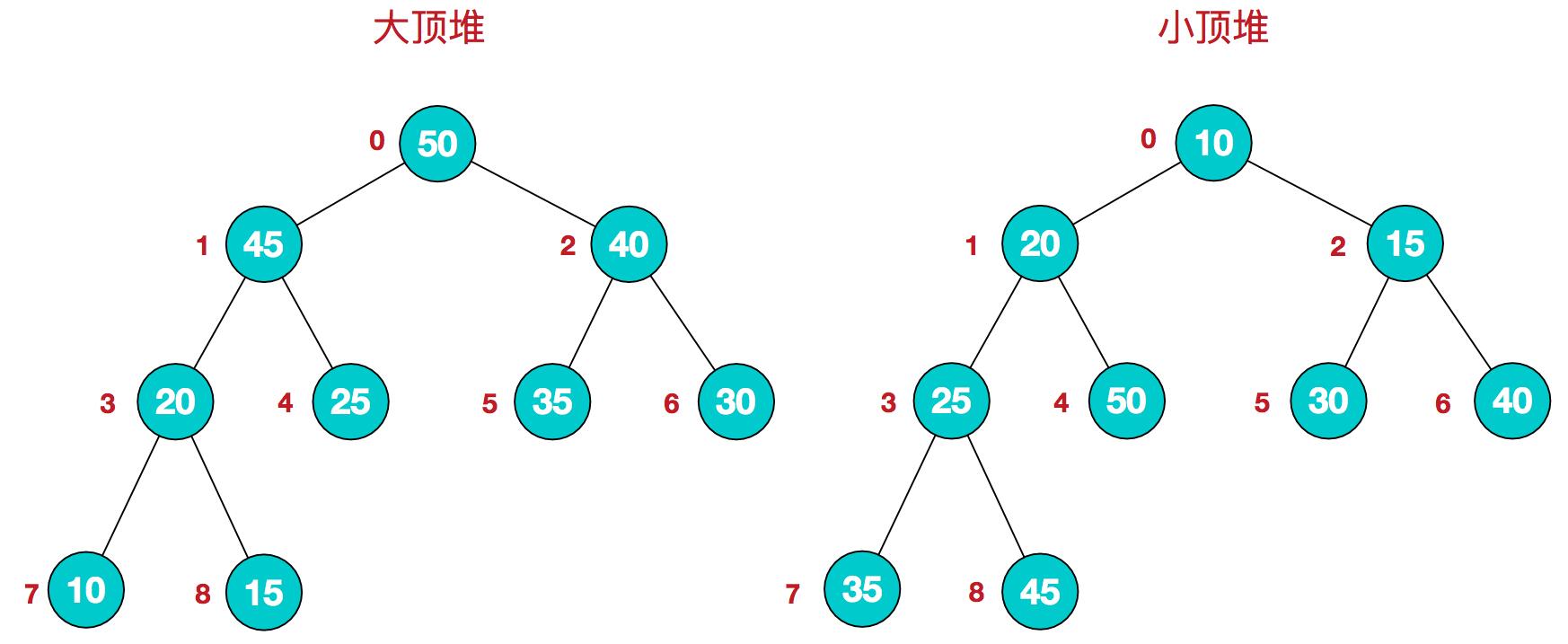
堆其实就是完全二叉树,看堆要首先知道大顶堆、小顶堆。
每个结点的值都大于或等于其左右孩子结点的值,称为大顶堆;或者每个结点的值都小于或等于其左右孩子结点的值,称为小顶堆。
大顶堆:arr[i] >= arr[2i+1] && arr[i] >= arr[2i+2]
小顶堆:arr[i] <= arr[2i+1] && arr[i] <= arr[2i+2]
原理
将待排序序列构造成一个大顶堆(升序采用大顶堆,降序采用小顶堆),此时,整个序列的最大值就是堆顶的根节点。将其与末尾元素进行交换,此时末尾就为最大值。然后将剩余n-1个元素重新构造成一个堆,这样会得到n个元素的次小值。如此反复执行,便能得到一个有序序列了
代码
1 | public static void heapSort(int[] arr) { |
复杂度
如果只是建立堆的过程,时间复杂度为O(N)
时间复杂度O(N*logN)
额外空间复杂度O(1)
快速排序
快速排序不是一种稳定的排序算法,也就是说,多个相同的值的相对位置也许会在算法结束时产生变动。
假定在待排序的记录序列中,存在多个具有相同的关键字的记录,若经过排序,这些记录的相对次序保持不变,即在原序列中,r[i]=r[j],且r[i]在r[j]之前,而在排序后的序列中,r[i]仍在r[j]之前,则称这种排序算法是稳定的;否则称为不稳定的。
原理
我先说说经典快排的思路吧。
将数组分成两部分,一部分是小于等于某个数的,一部分是大于等于某个数的。这两部分初始指针在数组的左(L)右(R)两头,此时L和R分别是一个边界点。
1.先定义less区域和more区域,代表比数组中某一个数更小更大的区域。初始less区域是L-1以左的部分,more区域是R以右的区域
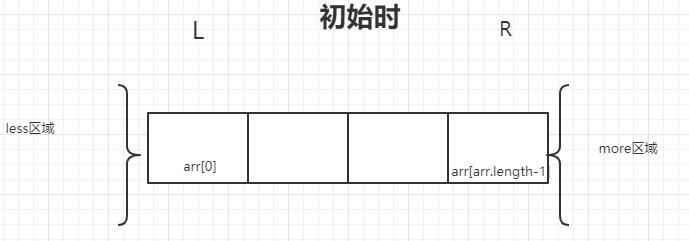
2.第一回合,从数组左边开始。若L指针指的节点值小于某个数值,less区域向右移动一个位置 swap(arr,++less,L++);,L节点位置+1准备下一个回合;若它大于这个数值,more区域向左扩张一格,然后将这个节点放到more区域swap(arr,--more,L++);,L节点位置+1准备下一个回合;若他等于这个数值,什么也不管,只是L节点位置+1准备下一个回合。
3.重复上述过程,得到了一个数组,他的L指针右边时小于某个数的,R的右边时大于某个数的。[L,R]这个区间是等于某个数的。
4.返回这个都是相同数的数组的左边界、右边界
5.不断递归
经典快排有一个弊端。左部分和右部分的规模不一样或者有一个部分规模特别大,算法效率会变差。举个栗子,如果我有个数组[1,1,3,4,7,6,1,2,1,5,1,7],我指定的某个数字是7,那么那么排序后就变成了[1,1,1,1,1,2,3,4,5,6,7],经典快排结束后只搞定了一个一个区间(<7的区间),复杂度就从理想状态下的O(N)变成了O(N²)
然后就有了改进后的随机快排。
随机快排比经典快排多了一个选随机数的过程 swap(arr, L + (int) (Math.random() * (R - L + 1)), R);。就是随机生成某个数,这样生成的区间虽然也会出现上述经典快排的恶劣情况,但是此时的复杂度就从原来的恶劣事件变成了有概率恶劣事件,但总体期望是好的。这就变成了一个概率问题。
代码
以下为随机快排
1 | public static void main(String[] args) { |
复杂度
科学家数学证明,长期期望的时间复杂度为O(logN*N)
快速排序可以做到稳定性问题,非常难,要知道的可以谷歌“01 stable sort” ,反正我不会。
归并排序
原理
1.和上题一样,先定义左边界L右边界R数组中,然后定义一个中间值mid = (r-l)/2
2.递归,在边界内部不断的找中间值mid
实现
1 | //归并排序 |
复杂度
时间复杂度O(N*logN)
额外空间复杂度O(N),归并排序的额外空间复杂度可以变成O(1),但是非常难,我没花时间研究,要知道的可以谷歌“归并排序 内部缓存法”
这里的时间复杂度怎么算出来的呢?有一个master定理:
T(N) = a*T(N/b) + O(N^d)
其中 a >= 1 and b > 1 是常量,其表示的意义是n表示问题的规模,a表示递归的次数也就是生成的子问题数,b表示每次递归是原来的1/b之一个规模。 如下:
1) log(b,a) > d -> 复杂度为O(N^log(b,a))
2) log(b,a) = d -> 复杂度为O(N^d * logN)
3) log(b,a) < d -> 复杂度为O(N^d)
这里,归并排序中b=2,a=2.
非基于比较的排序
非基于比较的排序,与被排序的样本的实际数据状况很有关系,所以实际中并不经常使用
桶排序
原理
1.找到一个数组中最大数的值
2.定义(最大数+1)个桶
3.将数组的数放到对应编号相同的桶中,每放进一个数,桶里面的数值加一
4.依次从小输出这个桶,桶里的元素出现几次就输出几个桶的编号
代码
1 | // only for 0~200 value |
复杂度
时间复杂度O(N)
额外空间复杂度O(N)
结束
此片完了~ 想要了解更多精彩新姿势?
请访问我的个人博客 本篇为原创内容,已在个人博客率先发表,随后CSDN,segmentfault,掘金,简书,开源中国同步发出。如有雷同,缘分呢兄弟。赶快加个好友~
